Week 9: Xarray for multidimensional gridded data¶
Grading:¶
- Total: 100
- Complete the example code: 20
- Exercise: 13
- Assignment: 57
- Comments clearly and concisely explain the purpose behind code: 10
In previous lecture, we saw how Pandas provided a way to keep track of additional "metadata" surrounding tabular datasets, including "indexes" for each row and labels for each column. These features, together with Pandas' many useful routines for all kinds of data munging and analysis, have made Pandas one of the most popular python packages in the world.
However, not all environmental science datasets easily fit into the "tabular" model (i.e. rows and columns) imposed by Pandas. In particular, we often deal with multidimensional data. By multidimensional data (also often called N-dimensional), I mean data with many independent dimensions or axes. For example, we might represent Earth's surface temperature $T$ as a three dimensional variable
$$ T(x, y, t) $$
where $x$ is longitude, $y$ is latitude, and $t$ is time.
The point of xarray is to provide pandas-level convenience for working with this type of data.
1. What is Xarray?¶
1.1 Xarray data model¶
Here is an example of how we might structure a dataset for a weather forecast:
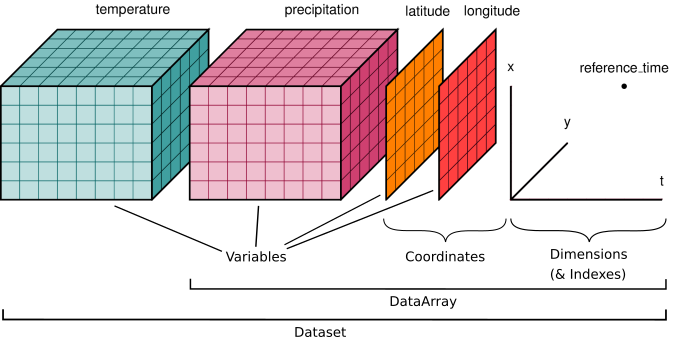
You'll notice multiple data variables (temperature, precipitation), coordinate variables (latitude, longitude), and dimensions (x, y, t). We'll cover how these fit into Xarray's data structures below.
1.2 Xarray functionality¶
Xarray doesn’t just keep track of labels on arrays – it uses them to provide a powerful and concise interface. For example:
Apply operations over dimensions by name:
x.sum('time').Select values by label (or logical location) instead of integer location:
x.loc['2014-01-01']orx.sel(time='2014-01-01').Mathematical operations (e.g.,
x - y) vectorize across multiple dimensions (array broadcasting) based on dimension names, not shape.Easily use the split-apply-combine paradigm with groupby:
x.groupby('time.dayofyear').mean().Database-like alignment based on coordinate labels that smoothly handles missing values:
x, y = xr.align(x, y, join='outer').Keep track of arbitrary metadata in the form of a Python dictionary:
x.attrs.
The N-dimensional nature of xarray’s data structures makes it suitable for
dealing with multi-dimensional scientific data, and its use of dimension names
instead of axis labels (dim='time' instead of axis=0) makes such arrays much
more manageable than the raw numpy ndarray: with xarray, you don’t need to keep
track of the order of an array’s dimensions or insert dummy dimensions of size 1
to align arrays (e.g., using np.newaxis).
The immediate payoff of using xarray is that you’ll write less code. The long-term payoff is that you’ll understand what you were thinking when you come back to look at it weeks or months later.
1.3 Xarray data structures¶
Like Pandas, xarray has two fundamental data structures:
- a
DataArray, which holds a single multi-dimensional variable and its coordinates - a
Dataset, which holds multiple variables that potentially share the same coordinates
A DataArray has four essential attributes:
values: anumpy.ndarrayholding the array’s valuesdims: dimension names for each axis (e.g.,('x', 'y', 'z'))coords: a dict-like container of arrays (coordinates) that label each point (e.g., 1-dimensional arrays of numbers, datetime objects or strings)attrs: anOrderedDictto hold arbitrary metadata (attributes)
1.4 Import Xarray packages¶
# First import xarray
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
2. Exploring Xarray data structure¶
Array data can be stored in the following standard formats:
- Hierarchical Data Format (HDF5) - Container for many arrays
- Network Common Data Form (NetCDF) - Container for many arrays which conform to the NetCDF data model
- Zarr - New cloud-optimized format for array storage
Here we will focus on using NetCDF data. NetCDF is widely used in international projects, governmental organizations (like NASA, NOAA), and academic institutions. Its adoption in climate models, geospatial data, remote sensing, and weather forecasting systems cements its role as a go-to format for many researchers. NetCDF efficiently handles multidimensional data (e.g., space, time, and variables like temperature or pressure), which is crucial in environmental science analysis where data often have complex, high-dimensional structures. It is commonly used for time series, 3D models, and spatially distributed data.
Python's xarray library is widely used for handling NetCDF data due to its powerful and flexible features tailored for working with labeled, multidimensional arrays.
2.1 Reading Xarray data¶
Here we use an example air temperature data from NCEP-NCAR Reanalysis .
Like Pandas, xarray also has a built-in function to easily read in NetCDF data as an xarray Dataset:
ds = xr.open_dataset('air.sig995.2023.nc')
ds
<xarray.Dataset> Size: 15MB
Dimensions: (lat: 73, lon: 144, time: 365, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Dimensions without coordinates: nbnds
Data variables:
air (time, lat, lon) float32 15MB ...
time_bnds (time, nbnds) float64 6kB ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1We can access "layers" of the Dataset (individual DataArrays) with dictionary syntax
ds["air"]
<xarray.DataArray 'air' (time: 365, lat: 73, lon: 144)> Size: 15MB
[3836880 values with dtype=float32]
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -82.5 -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes:
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NCEP Reanalysis Daily Averages
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]We can save some typing by using the "attribute" or "dot" notation. This won't work for variable names that clash with built-in method names (for example, mean).
ds.air
<xarray.DataArray 'air' (time: 365, lat: 73, lon: 144)> Size: 15MB
[3836880 values with dtype=float32]
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -82.5 -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes:
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NCEP Reanalysis Daily Averages
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]2.2 What is included in xarray Dataset?¶
The output consists of:
- a summary of all dimensions of the
Dataset(time: 365, lat: 73, lon: 144): this tells us that the first dimension is namedtimeand has a size of365, the second dimension is namedlatand has a size of73, and the third dimension is namedlonand has a size of365. Because we will access the dimensions by name, the order doesn't matter. - an unordered list of coordinates or dimensions with coordinates with one item per line. Each item has a name, one or more dimensions in parentheses, a dtype and a preview of the values.
- an alphabetically sorted list of dimensions without coordinates (if there are any)
- an unordered list of attributes, or metadata
DataArray¶
The DataArray class consists of an array (data) and its associated dimension names, labels, and attributes (metadata).
da = ds["air"]
da
<xarray.DataArray 'air' (time: 365, lat: 73, lon: 144)> Size: 15MB
[3836880 values with dtype=float32]
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -82.5 -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes:
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NCEP Reanalysis Daily Averages
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]We can also access the data array directly:
ds.air.data
array([[[246.57498, 246.57498, 246.57498, ..., 246.57498, 246.57498,
246.57498],
[248.04999, 247.97498, 247.92499, ..., 248.29999, 248.19998,
248.12498],
[255.52498, 256.07498, 256.62497, ..., 253.99998, 254.47499,
254.99998],
...,
[251.32498, 251.49997, 251.69998, ..., 250.97498, 251.04999,
251.14998],
[251.57498, 251.59998, 251.62497, ..., 251.575 , 251.575 ,
251.57498],
[251.22498, 251.22498, 251.22498, ..., 251.22498, 251.22498,
251.22498]],
[[248.19998, 248.19998, 248.19998, ..., 248.19998, 248.19998,
248.19998],
[253.39998, 253.39998, 253.34998, ..., 253.34998, 253.37497,
253.37498],
[259.3 , 259.97498, 260.55 , ..., 257.14996, 257.87497,
258.59998],
...,
[252.89996, 253.32497, 253.64996, ..., 251.84998, 252.17497,
252.52498],
[252.72498, 252.79999, 252.84998, ..., 252.59998, 252.62497,
252.69998],
[252.79997, 252.79997, 252.79997, ..., 252.79997, 252.79997,
252.79997]],
[[248.20001, 248.20001, 248.20001, ..., 248.20001, 248.20001,
248.20001],
[256.15 , 255.94998, 255.725 , ..., 256.65 , 256.5 ,
256.325 ],
[263.32498, 263.625 , 263.925 , ..., 261.95 , 262.475 ,
262.925 ],
...,
[253.27501, 253.40001, 253.52501, ..., 252.875 , 252.95 ,
253.1 ],
[252.475 , 252.475 , 252.5 , ..., 252.42499, 252.42499,
252.44998],
[252.025 , 252.025 , 252.025 , ..., 252.025 , 252.025 ,
252.025 ]],
...,
[[248.025 , 248.025 , 248.025 , ..., 248.025 , 248.025 ,
248.025 ],
[248.34999, 248.17499, 247.99998, ..., 248.74998, 248.625 ,
248.47499],
[252.275 , 252.22499, 252.15 , ..., 252.22499, 252.24998,
252.29999],
...,
[249.1 , 249.20001, 249.25 , ..., 248.92499, 248.975 ,
249.025 ],
[250.6 , 250.425 , 250.275 , ..., 251.125 , 250.925 ,
250.75 ],
[255.47499, 255.47499, 255.47499, ..., 255.47499, 255.47499,
255.47499]],
[[248.97499, 248.97499, 248.97499, ..., 248.97499, 248.97499,
248.97499],
[251.825 , 251.67499, 251.44998, ..., 252.29999, 252.15 ,
252.02498],
[258.95 , 259.175 , 259.325 , ..., 257.65 , 258.125 ,
258.6 ],
...,
[249.72499, 249.8 , 249.87498, ..., 249.57501, 249.575 ,
249.62498],
[254.29999, 254.2 , 254.07498, ..., 254.84999, 254.65 ,
254.49998],
[258.1 , 258.1 , 258.1 , ..., 258.1 , 258.1 ,
258.1 ]],
[[253.82498, 253.82498, 253.82498, ..., 253.82498, 253.82498,
253.82498],
[257.3 , 257.4 , 257.47498, ..., 257. , 257.07498,
257.19998],
[257.65 , 258.75 , 259.8 , ..., 254.42499, 255.44998,
256.57498],
...,
[253.82498, 253.79999, 253.72499, ..., 253.87497, 253.84998,
253.84998],
[255.62498, 255.47499, 255.34998, ..., 256.12497, 255.92499,
255.72498],
[258.72498, 258.72498, 258.72498, ..., 258.72498, 258.72498,
258.72498]]], dtype=float32)
Named dimensions¶
.dims are the named axes of your data. They may (dimension coordinates) or may not (dimensions without coordinates) have associated values.
In this case we have 2 spatial dimensions (latitude and longitude are stored with shorthand names lat and lon) and one temporal dimension (time).
ds.air.dims
('time', 'lat', 'lon')
Coordinates¶
.coords is a simple dict-like data container
for mapping coordinate names to values.
Here we see the actual timestamps and spatial positions of our air temperature data:
ds.air.coords
Coordinates: * lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -82.5 -85.0 -87.5 -90.0 * lon (lon) float32 576B 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5 * time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes¶
.attrs is a dictionary that can contain arbitrary Python objects (strings, lists, integers, dictionaries, etc.) containing information about your data. Your only
limitation is that some attributes may not be writeable to certain file formats.
ds.air.attrs
{'long_name': 'mean Daily Air temperature at sigma level 995',
'units': 'degK',
'precision': np.int16(2),
'GRIB_id': np.int16(11),
'GRIB_name': 'TMP',
'var_desc': 'Air temperature',
'dataset': 'NCEP Reanalysis Daily Averages',
'statistic': 'Mean',
'parent_stat': 'Individual Obs',
'valid_range': array([185.16, 331.16], dtype=float32),
'level_desc': '0.995 sigma',
'actual_range': array([191.4 , 318.05], dtype=float32)}
# assign your own attributes!
ds.air.attrs["new_attr"] = "trial dataset in class"
ds.air.attrs
{'long_name': 'mean Daily Air temperature at sigma level 995',
'units': 'degK',
'precision': np.int16(2),
'GRIB_id': np.int16(11),
'GRIB_name': 'TMP',
'var_desc': 'Air temperature',
'dataset': 'NCEP Reanalysis Daily Averages',
'statistic': 'Mean',
'parent_stat': 'Individual Obs',
'valid_range': array([185.16, 331.16], dtype=float32),
'level_desc': '0.995 sigma',
'actual_range': array([191.4 , 318.05], dtype=float32),
'new_attr': 'trial dataset in class'}
3. Working with Labelled Data¶
Xarray's labels make working with multidimensional data much easier. Metadata provides context and provides code that is more legible. This reduces the likelihood of errors from typos and makes analysis more intuitive and fun!
3.1 Plot labelled data¶
## Without Xarray, let's try to use matplotlib to plot the data
temp = ds.air.data
plt.pcolormesh(temp[0,:,:])
<matplotlib.collections.QuadMesh at 0x33d0c16d0>

### Add Lat and Lon
temp = ds.air.data
lat = ds.air.lat.data
lon = ds.air.lon.data
plt.pcolormesh(lon, lat, temp[0,:,:])
<matplotlib.collections.QuadMesh at 0x33d0c12b0>

temp.mean(axis=1) ## what did I just do? I can't tell by looking at this line.
array([[280.59583, 280.43628, 280.28867, ..., 280.75656, 280.65207,
280.58704],
[280.29794, 280.4586 , 280.45416, ..., 280.25885, 280.03458,
280.04657],
[280.10754, 280.03354, 279.92673, ..., 280.4538 , 280.11682,
280.101 ],
...,
[280.65173, 280.88287, 280.90796, ..., 280.73325, 280.57697,
280.5192 ],
[280.89075, 281.15482, 281.1534 , ..., 281.20197, 280.81638,
280.6781 ],
[281.50757, 281.5658 , 281.36743, ..., 281.63388, 281.364 ,
281.33322]], dtype=float32)
ds.air.isel(time=0).plot()
<matplotlib.collections.QuadMesh at 0x3394d1ca0>

ds.air.mean(dim="time").plot()
<matplotlib.collections.QuadMesh at 0x33d3ae9d0>

3.2 Selecting Data (Indexing)¶
We can always use regular numpy indexing and slicing on DataArrays
3.2.1 Position-based Indexing¶
Indexing a DataArray directly works (mostly) just like it does for numpy ndarrays, except that the returned object is always another DataArray:
This approach however does not take advantage of the dimension names and coordinate location information that is present in a Xarray object.
# Select the data by the column and row index.
da[:, 20, 40]
<xarray.DataArray 'air' (time: 365)> Size: 1kB
array([264.69998, 265. , 265.325 , ..., 270.22498, 268.325 , 266.59998],
dtype=float32)
Coordinates:
lat float32 4B 40.0
lon float32 4B 100.0
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in class# The first element in the data.
da[0,0,0]
<xarray.DataArray 'air' ()> Size: 4B
array(246.57498, dtype=float32)
Coordinates:
lat float32 4B 90.0
lon float32 4B 0.0
time datetime64[ns] 8B 2023-01-01
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in class3.2.2 Positional Indexing Using Dimension Names¶
Remembering the axis order can be challenging even with 2D arrays:
- is
np_array[0,3]the first row and third column or first column and third row? - or did I store these samples by row or by column when I saved the data?!
The difficulty is compounded with added dimensions.
Xarray objects eliminate much of the mental overhead by allowing indexing using dimension names instead of axes numbers:
da.isel(lat=0, lon=0).plot();

Slicing is also possible similarly:
da.isel(time=slice(0, 20), lat=0, lon=0).plot();

Using the isel method, the user can choose/slice the specific elements from a Dataset or DataArray.
So far, we have explored positional indexing, which relies on knowing the exact indices. But, what if you wanted to select data specifically for a particular latitude? It becomes challenging to determine the corresponding indices in such cases. Xarray reduce this complexity by introducing label-based indexing.
3.2.3 Label-based Indexing¶
To select data by coordinate labels instead of integer indices we can use sel instead of isel:
For example, let's select all data for Lat 25 °N and Lon 210 °E using sel :
da.sel(lat=25, lon=210).plot();

Similarly we can do slicing or filter a range using the .slice function:
# demonstrate slicing
da.sel(lon=slice(210, 215))
<xarray.DataArray 'air' (time: 365, lat: 73, lon: 3)> Size: 320kB
array([[[246.57498, 246.57498, 246.57498],
[245.04999, 245.14998, 245.27498],
...,
[254.42497, 254.54999, 254.64998],
[251.22498, 251.22498, 251.22498]],
[[248.19998, 248.19998, 248.19998],
[244.52498, 244.54997, 244.64996],
...,
[257.07498, 257.24997, 257.34998],
[252.79997, 252.79997, 252.79997]],
...,
[[248.97499, 248.97499, 248.97499],
[244.72499, 244.79999, 244.84999],
...,
[260.625 , 260.82498, 260.97498],
[258.1 , 258.1 , 258.1 ]],
[[253.82498, 253.82498, 253.82498],
[248.75 , 248.9 , 249.07498],
...,
[262.375 , 262.57498, 262.775 ],
[258.72498, 258.72498, 258.72498]]], dtype=float32)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -82.5 -85.0 -87.5 -90.0
* lon (lon) float32 12B 210.0 212.5 215.0
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in class# demonstrate slicing
da.sel(lat=slice(25, 50))
<xarray.DataArray 'air' (time: 365, lat: 0, lon: 144)> Size: 0B
array([], shape=(365, 0, 144), dtype=float32)
Coordinates:
* lat (lat) float32 0B
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in class# demonstrate slicing
da.sel(lat=slice(50, 25), lon=slice(210, 215))
<xarray.DataArray 'air' (time: 365, lat: 11, lon: 3)> Size: 48kB
array([[[281. , 281.22498, 282.09998],
[282.15 , 282.47498, 283.15 ],
...,
[295.55 , 295.12497, 294.97498],
[295.8 , 295.59998, 295.55 ]],
[[279.425 , 279.47498, 280.09998],
[280.94998, 281.34998, 281.875 ],
...,
[296.09998, 295.8 , 295.97498],
[296.25 , 295.9 , 295.8 ]],
...,
[[278.875 , 278.22498, 277.925 ],
[279.575 , 279.525 , 279.55 ],
...,
[292.47498, 291.675 , 291.625 ],
[293.675 , 292.82498, 292.475 ]],
[[278.2 , 278.02496, 278.97498],
[279.175 , 278.84998, 279.44998],
...,
[293.22498, 292.675 , 292.975 ],
[293.97498, 293.2 , 292.925 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 44B 50.0 47.5 45.0 42.5 40.0 ... 32.5 30.0 27.5 25.0
* lon (lon) float32 12B 210.0 212.5 215.0
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in classSo far, all the above will require us to specify exact coordinate values, but what if we don't have the exact values? We can use nearest neighbor lookups to address this issue:
3.2.4 Nearest Neighbor Lookups¶
The label based selection methods sel() support method and tolerance keyword argument. The method parameter allows for enabling nearest neighbor (inexact) lookups by use of the methods ffill (propagate last valid index forward), backfill or nearest:
da.sel(lat=52.25, lon=251.8998, method="nearest")
<xarray.DataArray 'air' (time: 365)> Size: 1kB
array([261.24997, 266.07498, 266.8 , ..., 273.1 , 267.15 , 268.675 ],
dtype=float32)
Coordinates:
lat float32 4B 52.5
lon float32 4B 252.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in classda.sel(lat=52.25, lon=251.8998, method="ffill")
<xarray.DataArray 'air' (time: 365)> Size: 1kB
array([264.99997, 268.32498, 266.5 , ..., 274.8 , 270.7 , 271.85 ],
dtype=float32)
Coordinates:
lat float32 4B 52.5
lon float32 4B 250.0
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in classtolerance argument limits the maximum distance for valid matches with an inexact lookup:
da.sel(lat=52.25, lon=251.8998, method="nearest", tolerance=2)
<xarray.DataArray 'air' (time: 365)> Size: 1kB
array([261.24997, 266.07498, 266.8 , ..., 273.1 , 267.15 , 268.675 ],
dtype=float32)
Coordinates:
lat float32 4B 52.5
lon float32 4B 252.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in classda.sel(lat=52.25, lon=198, method="nearest", tolerance=2)
<xarray.DataArray 'air' (time: 365)> Size: 1kB
array([277.4 , 276.37497, 275. , ..., 277.07498, 277.075 , 276.05 ],
dtype=float32)
Coordinates:
lat float32 4B 52.5
lon float32 4B 197.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Attributes: (12/13)
long_name: mean Daily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
... ...
statistic: Mean
parent_stat: Individual Obs
valid_range: [185.16 331.16]
level_desc: 0.995 sigma
actual_range: [191.4 318.05]
new_attr: trial dataset in class{tip}
All of these indexing methods work on the dataset too!
We can also use these methods to index all variables in a dataset simultaneously, returning a new dataset:
ds.sel(lat=52.25, lon=251.8998, method="nearest")
<xarray.Dataset> Size: 10kB
Dimensions: (time: 365, nbnds: 2)
Coordinates:
lat float32 4B 52.5
lon float32 4B 252.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31
Dimensions without coordinates: nbnds
Data variables:
air (time) float32 1kB 261.2 266.1 266.8 266.9 ... 273.1 267.1 268.7
time_bnds (time, nbnds) float64 6kB ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1Exercise 1: Select and plot the air temperature of New Brunswick,NJ (46.5653° N, 66.4619° W). (5 points)¶
Note: You will need to convert western degrees to a degree ranging from 0 to 360, subtract it from 360.
3.3 Datetime Indexing¶
Datetime indexing is a critical feature when working with time series data, which is a common occurrence in environmental sciences. Essentially, datetime indexing allows you to select data points or a series of data points that correspond to certain date or time criteria. This becomes essential for time-series analysis where the date or time information associated with each data point can be as critical as the data point itself.
Let's see some of the techniques to perform datetime indexing in Xarray:
3.3.1 Selecting data based on single datetime¶
Let's say we have a Dataset ds and we want to select data at a particular date and time, for instance, '2013-01-01' at 6AM. We can do this by using the sel (select) method, like so:
ds.sel(time='2023-05-01')
<xarray.Dataset> Size: 43kB
Dimensions: (lat: 73, lon: 144, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
time datetime64[ns] 8B 2023-05-01
Dimensions without coordinates: nbnds
Data variables:
air (lat, lon) float32 42kB 259.0 259.0 259.0 ... 222.2 222.2 222.2
time_bnds (nbnds) float64 16B ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1By default, datetime selection will return a range of values that match the provided string. For e.g. time="2023-01" will return all timestamps for that month:
ds.sel(time="2023-01")
<xarray.Dataset> Size: 1MB
Dimensions: (lat: 73, lon: 144, time: 31, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 248B 2023-01-01 2023-01-02 ... 2023-01-31
Dimensions without coordinates: nbnds
Data variables:
air (time, lat, lon) float32 1MB 246.6 246.6 246.6 ... 245.1 245.1
time_bnds (time, nbnds) float64 496B ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1# Or use month name
ds.sel(time="2023-May")
<xarray.Dataset> Size: 1MB
Dimensions: (lat: 73, lon: 144, time: 31, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 248B 2023-05-01 2023-05-02 ... 2023-05-31
Dimensions without coordinates: nbnds
Data variables:
air (time, lat, lon) float32 1MB 259.0 259.0 259.0 ... 209.9 209.9
time_bnds (time, nbnds) float64 496B ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 13.3.2 Selecting data for a range of dates¶
Now, let's say we want to select data between a certain range of dates. We can still use the sel method, but this time we will combine it with slice:
# This will return a subset of the dataset corresponding to Jan to March of 2023
ds.sel(time=slice('2023-01-01', '2023-03-31'))
<xarray.Dataset> Size: 4MB
Dimensions: (lat: 73, lon: 144, time: 90, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 720B 2023-01-01 2023-01-02 ... 2023-03-31
Dimensions without coordinates: nbnds
Data variables:
air (time, lat, lon) float32 4MB 246.6 246.6 246.6 ... 223.4 223.4
time_bnds (time, nbnds) float64 1kB ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1The slice function takes two arguments, start and stop, to make a slice that includes these endpoints. When we use slice with the sel method, it provides an efficient way to select a range of dates. The above example shows the usage of slice for datetime indexing.
3.3.3 Indexing with a DatetimeIndex or date string list¶
Another technique is to use a list of datetime objects or date strings for indexing. For example, you could select data for specific, non-contiguous dates like this:
dates = ['2023-07-09', '2023-10-11', '2023-12-24']
ds.sel(time=dates)
<xarray.Dataset> Size: 127kB
Dimensions: (lat: 73, lon: 144, time: 3, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 24B 2023-07-09 2023-10-11 2023-12-24
Dimensions without coordinates: nbnds
Data variables:
air (time, lat, lon) float32 126kB 274.6 274.6 274.6 ... 248.4 248.4
time_bnds (time, nbnds) float64 48B ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 13.3.4 Fancy indexing based on year, month, day, or other datetime components¶
In addition to the basic datetime indexing techniques, Xarray also supports "fancy" indexing options, which can provide more flexibility and efficiency in your data analysis tasks. You can directly access datetime components such as year, month, day, hour, day of week, etc. using the .dt accessor. Here is an example of selecting all data points from July across all years:
ds.sel(time=ds.time.dt.month == 7)
<xarray.Dataset> Size: 1MB
Dimensions: (lat: 73, lon: 144, time: 31, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 248B 2023-07-01 2023-07-02 ... 2023-07-31
Dimensions without coordinates: nbnds
Data variables:
air (time, lat, lon) float32 1MB 275.8 275.8 275.8 ... 212.2 212.2
time_bnds (time, nbnds) float64 496B ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1Or, if you wanted to select data from a specific day of each month, you could use:
ds.sel(time=ds.time.dt.day == 15)
<xarray.Dataset> Size: 506kB
Dimensions: (lat: 73, lon: 144, time: 12, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 96B 2023-01-15 2023-02-15 ... 2023-12-15
Dimensions without coordinates: nbnds
Data variables:
air (time, lat, lon) float32 505kB 244.9 244.9 244.9 ... 250.2 250.2
time_bnds (time, nbnds) float64 192B ...
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1Exercise 2: Select all data on Sunday only. (3 points)¶
Hint: Use the dayofweek function.
4. Xarray Computation¶
4.1 Arithmetic Operations¶
Similar to Pandas, xarray supports different kinds of arithmetic operations
ds['air_C'] = ds['air'] - 273.15
ds['air_C']
<xarray.DataArray 'air_C' (time: 365, lat: 73, lon: 144)> Size: 15MB
array([[[-26.575012, -26.575012, -26.575012, ..., -26.575012,
-26.575012, -26.575012],
[-25.100006, -25.175018, -25.225006, ..., -24.850006,
-24.950012, -25.02501 ],
[-17.625015, -17.075012, -16.525024, ..., -19.15001 ,
-18.675003, -18.15001 ],
...,
[-21.825012, -21.650024, -21.450012, ..., -22.175018,
-22.100006, -22.000015],
[-21.575012, -21.550018, -21.525024, ..., -21.574997,
-21.574997, -21.575012],
[-21.925018, -21.925018, -21.925018, ..., -21.925018,
-21.925018, -21.925018]],
[[-24.950012, -24.950012, -24.950012, ..., -24.950012,
-24.950012, -24.950012],
[-19.750015, -19.750015, -19.800018, ..., -19.800018,
-19.775024, -19.77501 ],
[-13.850006, -13.175018, -12.600006, ..., -16.00003 ,
-15.275024, -14.550018],
...
[-23.425003, -23.34999 , -23.27501 , ..., -23.574982,
-23.574997, -23.52501 ],
[-18.850006, -18.949997, -19.075012, ..., -18.300003,
-18.5 , -18.65001 ],
[-15.049988, -15.049988, -15.049988, ..., -15.049988,
-15.049988, -15.049988]],
[[-19.325012, -19.325012, -19.325012, ..., -19.325012,
-19.325012, -19.325012],
[-15.850006, -15.75 , -15.675018, ..., -16.149994,
-16.075012, -15.950012],
[-15.5 , -14.399994, -13.350006, ..., -18.725006,
-17.700012, -16.575012],
...,
[-19.325012, -19.350006, -19.425003, ..., -19.275024,
-19.300018, -19.300018],
[-17.52501 , -17.675003, -17.800018, ..., -17.025024,
-17.225006, -17.425018],
[-14.425018, -14.425018, -14.425018, ..., -14.425018,
-14.425018, -14.425018]]], dtype=float32)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -82.5 -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31# Generate a boolean mask where temperature is higher than 0˚C
ds['air_C'] > 0
<xarray.DataArray 'air_C' (time: 365, lat: 73, lon: 144)> Size: 4MB
array([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
...
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]])
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -82.5 -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 3kB 2023-01-01 2023-01-02 ... 2023-12-31# Generate a boolean mask where annual mean temperature is higher than 0˚C
ds['air_C'].mean(dim='time') > 0
<xarray.DataArray 'air_C' (lat: 73, lon: 144)> Size: 11kB
array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]])
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -82.5 -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 10.0 ... 350.0 352.5 355.0 357.5(ds['air_C'].mean(dim='time') > 0).plot()
<matplotlib.collections.QuadMesh at 0x33d749880>

# Apply the mask:
ds.where(ds['air_C'].mean(dim='time') > 0).mean(dim = 'time').air.plot()
<matplotlib.collections.QuadMesh at 0x33fda0130>

4.2 Broadcasting: expanding data¶
ds['air_C'].mean(dim='time').plot()
<matplotlib.collections.QuadMesh at 0x33fe80100>

(ds['air_C'].mean(dim='time')*np.cos(np.deg2rad(ds.lat))).plot()
<matplotlib.collections.QuadMesh at 0x33ff50b80>

# Make cos(lat) two dimensional
(xr.ones_like(ds['air_C'].mean(dim='time'))*np.cos(np.deg2rad(ds.lat))).plot()
<matplotlib.collections.QuadMesh at 0x353176eb0>

5. Xarray Groupby and Resample¶
5.1 groupby¶
We learned groupby in pandas, which can similary be applied to Xarray.
# Group by season
ds.groupby("time.season")
DatasetGroupBy, grouped over 'season' 4 groups with labels 'DJF', 'JJA', 'MAM', 'SON'.
# make a seasonal mean
seasonal_mean = ds.groupby("time.season").mean()
seasonal_mean
<xarray.Dataset> Size: 337kB
Dimensions: (season: 4, lat: 73, lon: 144, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* season (season) object 32B 'DJF' 'JJA' 'MAM' 'SON'
Dimensions without coordinates: nbnds
Data variables:
air (season, lat, lon) float32 168kB 249.7 249.7 ... 231.8 231.8
time_bnds (season, nbnds) float64 64B 1.958e+06 1.958e+06 ... 1.962e+06
air_C (season, lat, lon) float32 168kB -23.49 -23.49 ... -41.3 -41.3
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1The seasons are out of order (they are alphabetically sorted). This is a common
annoyance. The solution is to use .sel to change the order of labels
seasonal_mean = seasonal_mean.sel(season=["DJF", "MAM", "JJA", "SON"])
seasonal_mean
<xarray.Dataset> Size: 337kB
Dimensions: (season: 4, lat: 73, lon: 144, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* season (season) object 32B 'DJF' 'MAM' 'JJA' 'SON'
Dimensions without coordinates: nbnds
Data variables:
air (season, lat, lon) float32 168kB 249.7 249.7 ... 231.8 231.8
time_bnds (season, nbnds) float64 64B 1.958e+06 1.958e+06 ... 1.962e+06
air_C (season, lat, lon) float32 168kB -23.49 -23.49 ... -41.3 -41.3
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1seasonal_mean.air.plot(col="season")
<xarray.plot.facetgrid.FacetGrid at 0x353221520>

# Make the figure to 2x2 plots:
seasonal_mean.air.plot(col="season", col_wrap=2);

# Calculate zonal average
seasonal_mean.air.mean("lon").plot.line(hue="season", y="lat");

5.2 Resample¶
# resample to monthly frequency
ds.resample(time="ME").mean()
<xarray.Dataset> Size: 1MB
Dimensions: (time: 12, lat: 73, lon: 144, nbnds: 2)
Coordinates:
* lat (lat) float32 292B 90.0 87.5 85.0 82.5 ... -85.0 -87.5 -90.0
* lon (lon) float32 576B 0.0 2.5 5.0 7.5 ... 350.0 352.5 355.0 357.5
* time (time) datetime64[ns] 96B 2023-01-31 2023-02-28 ... 2023-12-31
Dimensions without coordinates: nbnds
Data variables:
air (time, lat, lon) float32 505kB 249.3 249.3 249.3 ... 250.2 250.2
time_bnds (time, nbnds) float64 192B 1.955e+06 1.955e+06 ... 1.963e+06
air_C (time, lat, lon) float32 505kB -23.9 -23.9 ... -22.92 -22.92
Attributes:
Conventions: COARDS
title: mean daily NMC reanalysis (2014)
history: created 2017/12 by Hoop (netCDF2.3)
description: Data is from NMC initialized reanalysis\n(4x/day). These...
platform: Model
References: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reana...
dataset_title: NCEP-NCAR Reanalysis 1ds.resample(time="ME").mean().mean(dim =['lat','lon']).air.plot()
[<matplotlib.lines.Line2D at 0x3538c2c70>]

Exercise 3: Make a time series plot of the monthly mean temperature over Northern Hemisphere. (5 points)¶
6. Assignment¶
In this assignment, we will use Xarray to analyze top-of-atmosphere radiation data from NASA's CERES project.
 Public domain, by NASA, from Wikimedia Commons
Public domain, by NASA, from Wikimedia Commons
6.1 Open the dataset and display its contents. (3 points)¶
6.2 Print out the long_name attribute of each variable (3 points)¶
6.3 Calculate the time-mean of the entire dataset (3 points)¶
6.4 From 6.3, make a 2D plot of the the time-mean TOA longwave, shortwave, and incoming solar radiation flux for All-Sky conditions (9 points, 3 points each)¶
Note the sign conventions on each variable.
6.5 Add up the three variables above and verify (visually) that they are equivalent to the TOA net flux (8 points: 6 points for figures, 2 points for verification)¶
You have to pay attention to and think about the sign conventions for each variable in order to get this to work.
6.6 Calculate the global mean of TOA net radiation directly from the dataset (4 points)¶
Since the Earth is approximately in radiative balance, the net TOA radiation should be zero. But taking the naive mean from this dataset, you should find a number far from zero. Why?
The answer is that each "pixel" or "grid point" of this dataset does not represent an equal area of Earth's surface. So naively taking the mean, i.e. giving equal weight to each point, gives the wrong answer.
On a lat / lon grid, the relative area of each grid point is proportional to $\cos(\lambda)$. ($\lambda$ is latitude)
6.7 Create a weight array proportional to $\cos(\lambda)$ with a mean value of 1 (5 points)¶
Verify its mean is 1 and plot it. Be careful about radians vs. degrees. (3 points)
6.8 Redo your global mean TOA net radiation calculation with this weight factor (4 points)¶
Remember Xarray's handling of broadcasting. Don't make this harder than it needs to be.
6.9 Plot the time-mean cloud area fraction (day and night) (3 points)¶
6.10 Define boolean masks for low cloud area ($\le$ 25%) and high cloud area ($\ge$ 75%) (3 points)¶
Use the whole dataset, not the time mean.
6.13 Subset the dataset for NJ region (74˚W - 75.6˚W, 38.8˚N - 41.5˚N) and calculate the monthly climatology of the regional mean cloud area fraction (6 points)¶